
How to set success metrics for facility
digitalization AI projects
Even though everyone generally agrees that integrating machine learning systems into your organization should bring about massive efficiency gains, it’s stressful if you’re the first one trying to do it. How do you know if you’re choosing the right solution? How can you prove to your bosses that it was the right move?
The first metric that comes to mind is accuracy. Ceteris paribus—all other things being equal—if the machine is more accurate than a human doing the same task, it’s a no brainer. Of course, reality is never that simple. How exactly are you defining accuracy? Most folks mean “precision” when they talk about accuracy, but depending on the task at hand, it’s not always the best measure.
Accuracy metrics: Precision, recall, & harmonic mean
Precision and recall are measures of relevance. Let’s break down how we might use them if we want to build an asset hierarchy using AI. Assuming we’ve got a jumbled corpus of all kinds of engineering drawings for a particular FPSO, one of the first steps we’d take is to search for P&IDs because they contain most of the information we’re looking for. Now, these P&IDs are scanned documents (i.e., images), so we won’t be able to do a simple text search of “piping and instrumentation diagram”. Instead, we’ll use an image classification model to separate the P&IDs from the rest.
Precision, the metric you’re probably most familiar with, is a fraction of how many documents the model says are P&IDs actually are P&IDs (known as true positives).
Recall, an alternate metric, takes false negatives into account. These would be any real P&IDs in the corpus that the model failed to identify.
For you visual learners, here’s a nice graphic that distinguishes the two:
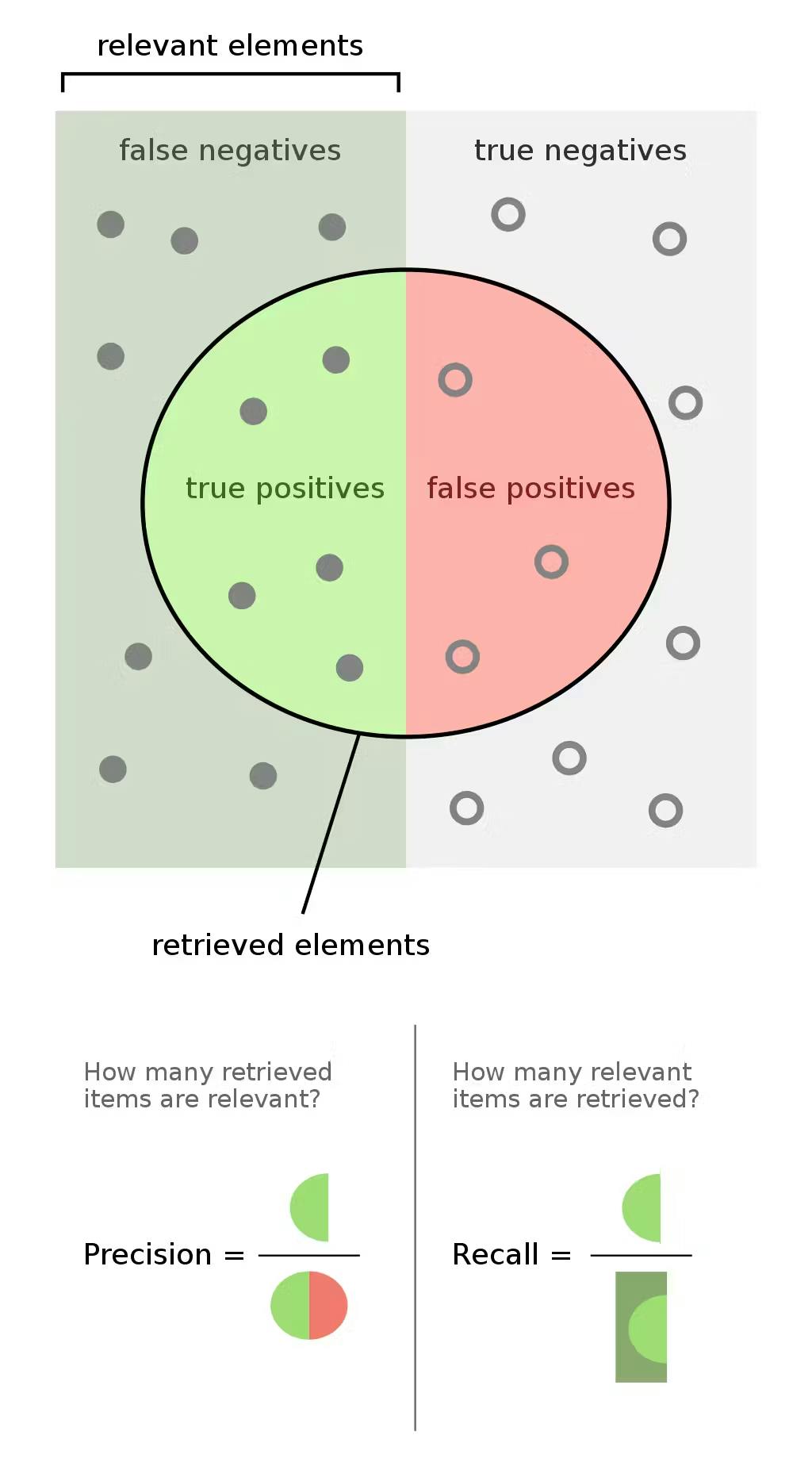
Source: Wikimedia Commons
Let’s say the model classified 30 documents as P&IDs, but only 20 actually were P&IDs. Precision would be ⅔, or 66%. However, it failed to identify another 40 real P&IDs in the corpus, recall would only be ⅓, or 33%.
Which should you use—do you need to choose one over the other? In most cases, you’d probably want to take both equally into consideration. But for this particular task, we’d give recall greater weight. That’s because it’s crucial that we find all the P&IDs, and we don’t care if a few single line diagrams or other engineering drawings get tossed in the mix. Optimizing for precision would mean losing valuable information, rendering your asset hierarchy useless.
For other tasks where we want a balanced measure of the two, we calculate an F1 score, also known as the harmonic mean. It’s an approximative average of the two when the values are close (see here if you want to understand the math behind it).
Precision, recall, and F1 are the most common machine learning metrics for most classification tasks. Things get a little more complicated when we look at models like object detection, but understanding these three measures will get you most of the way.
What’s an acceptable accuracy threshold in a business context?
It’s tempting to set a very high threshold because of state-of-the-art (SOTA) results produced by the machine learning research sphere. Bear in mind, though, that most of these results are published on clean, academic datasets. For real world business tasks, data is dirty, limited, and often incomplete. If you’re benchmarking against SOTA, you’re bound to be disappointed.
In that case, how should you go about setting an acceptable threshold for machine learning models, whether you’re sourcing them externally or building internally?
Well, accuracy definitely needs to be better than random chance, or the model is worthless. So for a two-class classification model that tries to identify P&IDs vs. all other drawings, it needs to perform better than 50%.
Your next point of reference should be accuracy and speed compared to a human performing the same task. If the model is less accurate than a human with an F1 score of 75%, but is able to crunch through the information in a fraction of the time (even with time for any required human remediation factored in), the answer is clear. Time saved is the business metric, and it outweighs the model metrics.
Alright, so that covers your decision if you have zero automation in place, and are looking at a single vendor or developing a solution in-house. If you’re comparing vendors or thinking of upgrading your system, there are a couple of other elements to consider. A major factor is whether your result requires 100% accuracy. We’ve said this many times and we’ll say it again: No machine learning model can achieve 100% accuracy, unless it’s overfitting to the task. If you require 100% accuracy, a human needs to come into the loop. If that’s the case, a vendor with an integrated method for remediation can outweigh one relying only on model performance.
Let’s go back to the asset hierarchy exercise. You’ve got your P&IDs, but now you need to extract information like instrument tags, line IDs, equipment numbers, etc. You’re comparing solutions from two vendors:
- Vendor A can extract information with an F1 score of 89%, but has no seamless method for remediation—you’ll need to create your own workflow for it.
- Vendor B can extract information with an F1 score of only 85%, but has an interface for easy remediation.
The information in your asset hierarchy needs to be 100% correct because it’s the basis for your digital twin and subsequent facility maintenance planning. With both vendors, remediation is required. Having that ability integrated into the solution is critical because it saves a significant amount of time—even if the machine learning model has lower accuracy and requires more correction. Trying to check a list of 50 extracted instrument tags in an Excel spreadsheet against one P&ID is already a nightmare. Now do that for a few hundred more P&IDs. Instead, the software should overlay results directly onto the P&ID for easy corrections.
Of course, if the accuracy gap between the two vendors is large, for example if Vendor B had an F1 of 60%, the remediation interface won't matter much when compared to Vendor A because you'll need to correct nearly half of the results. And for cases where remediation is unnecessary, you should definitely go for Vendor A.
Ultimately, thinking about model accuracy is a good starting point for measuring the success of your machine learning initiative. It’s essential, however, to put it into context because you might find that precision isn’t the most important factor for meeting your end goals.
Recommended Posts

8/15/2024
A new era of enterprise search for facilities
(Part II): Data preparation
Before implementing new search technology, data cleanup and preparation is critical. Here's what you need to do.

8/1/2024
A new era of enterprise search for facilities
Enterprise search is changing for facility operators—out with the file hierarchies and in with the information networks.

12/16/2022
Industry 4.0: The Unstructured Data Perspective
How to build a contextual platform that will be the launching pad for every one of your Industry 4.0 initiatives.