
OCR could be hurting your digital twin initiatives
We’ve noticed a recurring theme in our discussions with clients striving to create digital twins of their facilities from unstructured legacy documents. Most folks have heard of optical character recognition (OCR), know that it’s used for content extraction, and believe it’s fine to just apply it to all types of documents in a blanket format. Done and dusted.
That’s not at all the case. Vendors selling OCR-only solutions have obviously glossed over many important details in order to close the deal. Down the road, customers become understandably frustrated that the solutions don’t work as advertised.
Understanding when to apply OCR is critical because it affects the speed, accuracy, and ultimately, cost of your digitization process.
When to use OCR: What is a machine readable document?
Before you can decide whether or not you actually need OCR, you need to understand what a machine readable document is.
Without getting too deep into the weeds here, an easy way to tell if a document is machine readable is if you can select and search the text in it, like a Microsoft Word document. You can only do that because the machine recognizes it as a text format. You can also do this with many types of PDFs, because they were saved through a native program like Microsoft Word.
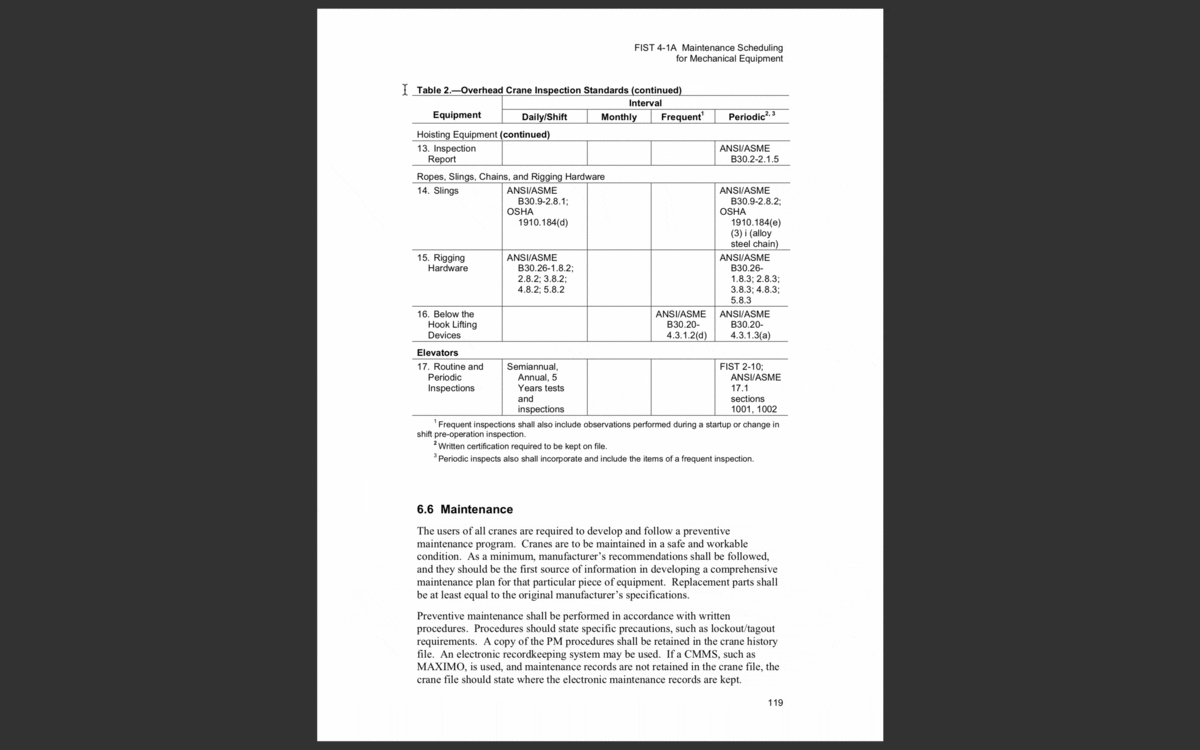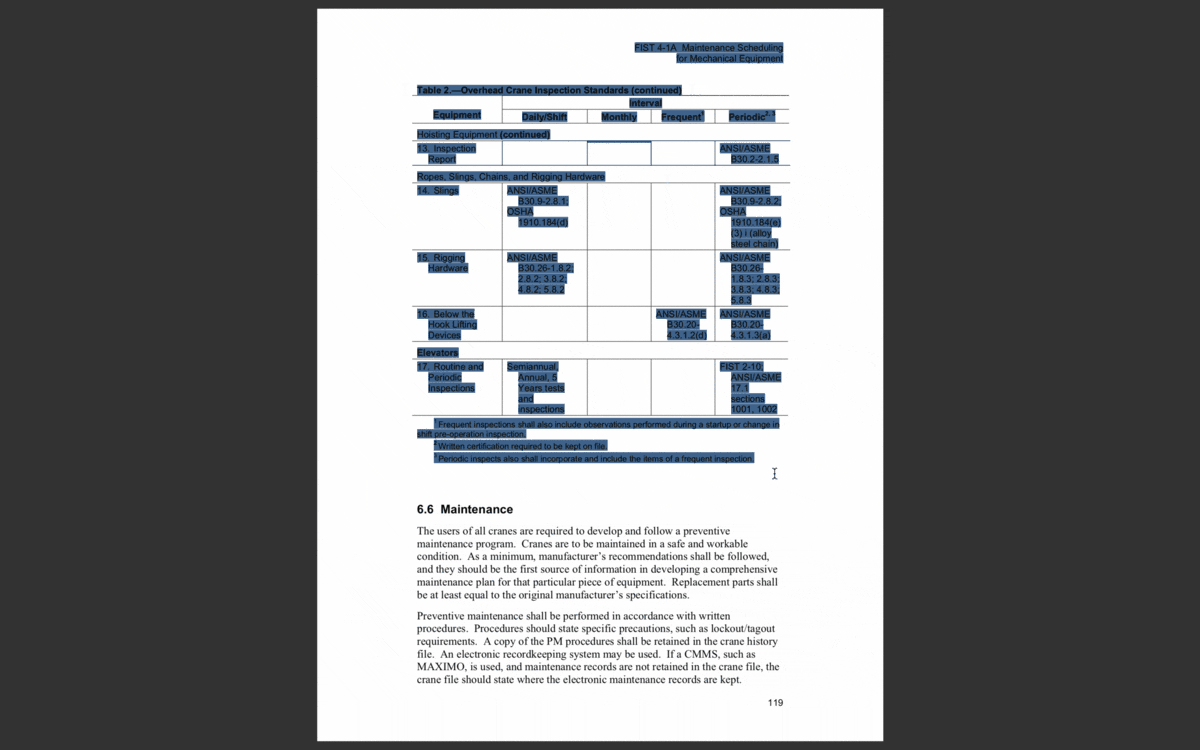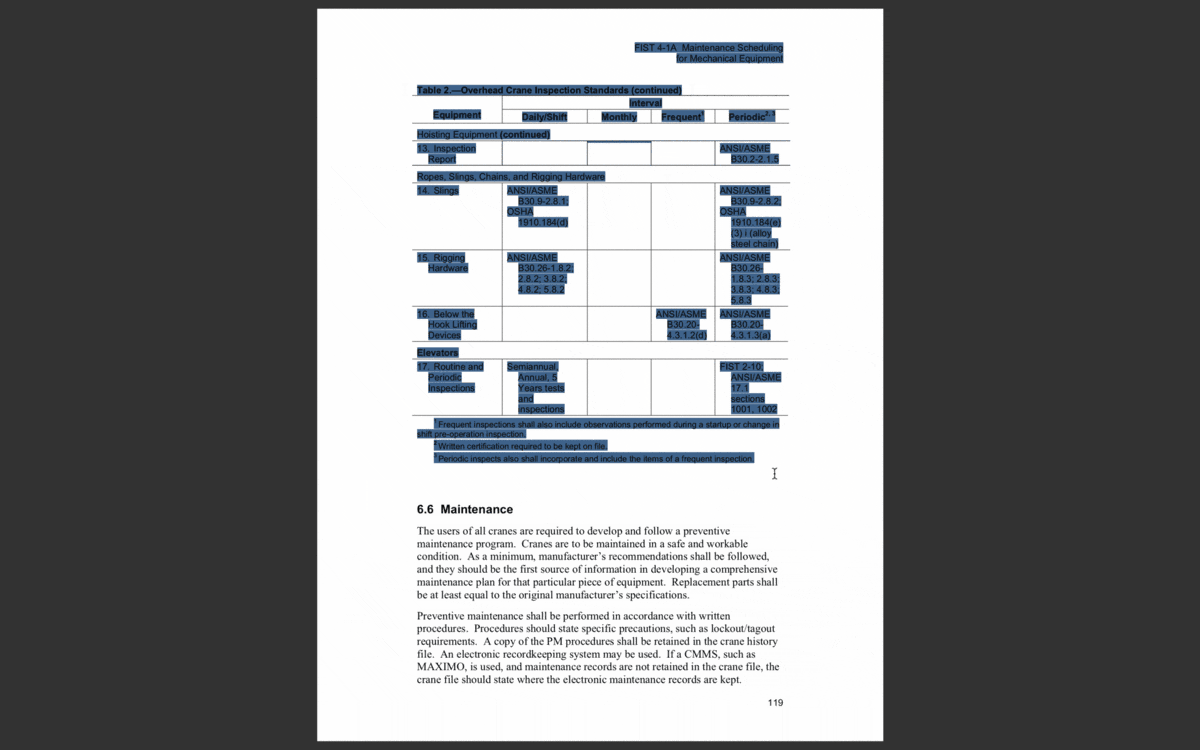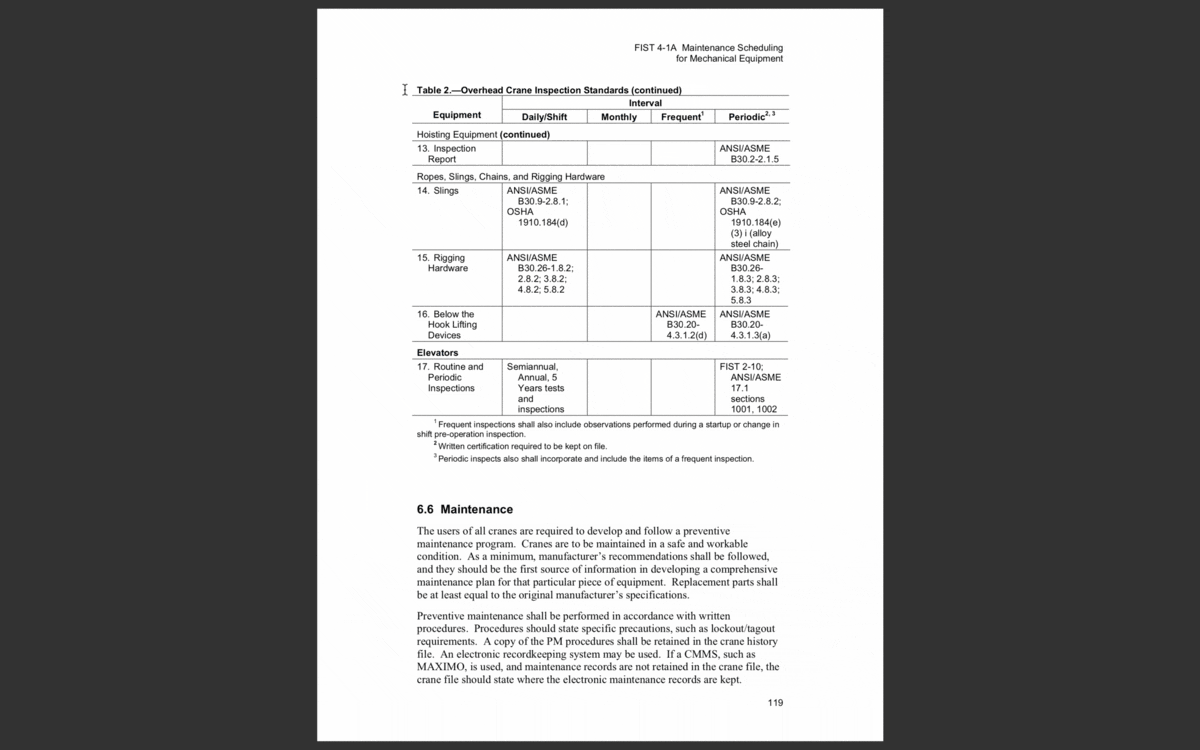
In a machine readable document, you can select (and search) individual words.
Now here’s where it might get a little confusing. Some PDFs are NOT machine readable. Why? Because they’re actually scanned documents, so they’re only images—like if you took a picture of your Microsoft Word document, and then saved that as a PDF. That means the text is now an image, and therefore unsearchable by a machine.
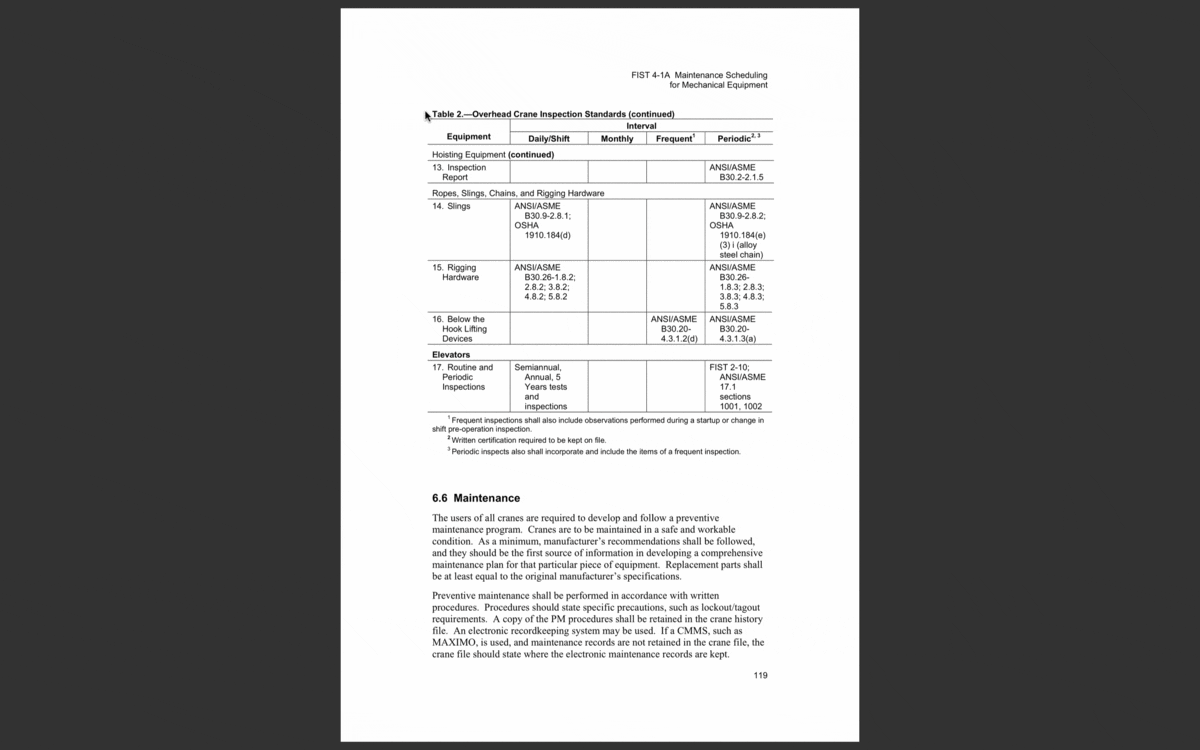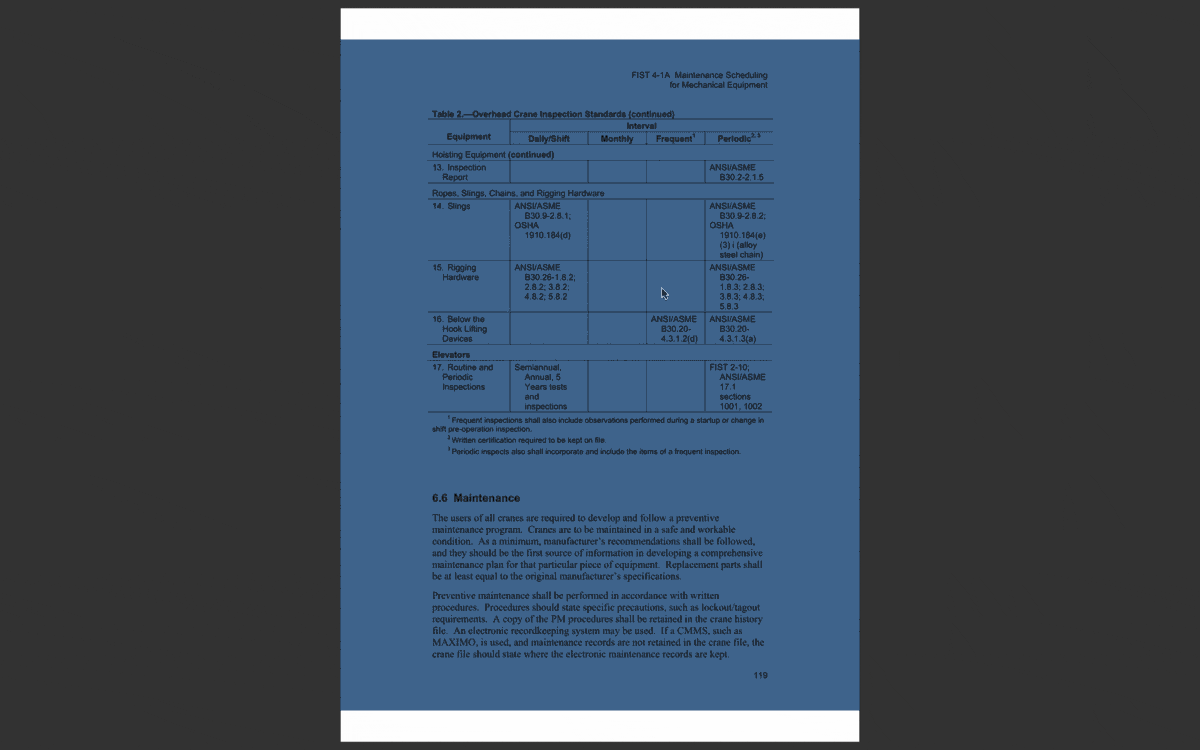
Scanned document: Unable to select individual words—instead, the software selects the entire area of the document, including blank space.
This is where OCR comes in.
OCR is a series of machine learning algorithms trained to detect areas of text in an image, and then predict what each character is. And since no generalizable machine learning algorithm can achieve 100% accuracy, when you string a bunch of algorithms together like in OCR, your overall accuracy is bound to drop a lot. That doesn’t mean OCR isn’t a good tool—far from it. Remember, a machine doesn’t know that the text you see in the scanned document is text, but OCR can quickly and automatically convert it into machine readable text. Imagine if a human tried to do this for hundreds of thousands of documents. Basically impossible.
However, depending on the task, it may be important to bring a human into the loop to review information extracted via OCR. If you’re extracting tags from P&IDs for your asset hierarchy, for example, it’s extremely important for a human to remediate any errors because that’s the foundation for your entire operations and maintenance plan moving forward.
So...why shouldn’t I just use OCR for all of my documents? Isn’t that simpler?
Conceptually, maybe, but practically, not at all.
Remember:
- No generalizable machine learning algorithm can achieve 100% accuracy.
- Machine readable documents contain 100% original, native text.
By applying OCR to documents that are actually machine readable, you’re wasting time running the conversion process when your machine could just directly access the information in the document. On top of that, you’re introducing errors. A human then needs to come into the loop to correct them (if 100% accuracy is required), costing you even more time and money.
Partially readable documents
Alright, there’s one more wrench in the works: Partially readable documents. These types of documents contain normal machine readable text, but the creator of the document may have pasted a picture, chart, or a screenshot of a table into the document. Dilemma: Should you OCR everything, and introduce error into the native text, or lose the information located in the chart or table?
Fortunately, there’s a solution for that. You can use deep learning to identify and separate different components on a page, allowing you to preserve the native text while still being able to capture the information located in non-readable sections.

Cenozai’s document processing pipeline automatically analyzes document layout to ensure all information is captured while preserving native text accuracy.
Beware snake oil
When looking for service providers to help you digitize legacy documents and engineering drawings for your Industry 4.0 initiatives, observe if they ask whether your documents are machine readable or scanned. If they don’t have a way to identify the different document types and separate them into the appropriate pipelines, it’s a red flag. It likely means they plan to just OCR everything, and you won’t get the results you expected.
Recommended Posts

8/15/2024
A new era of enterprise search for facilities
(Part II): Data preparation
Before implementing new search technology, data cleanup and preparation is critical. Here's what you need to do.

8/1/2024
A new era of enterprise search for facilities
Enterprise search is changing for facility operators—out with the file hierarchies and in with the information networks.

12/16/2022
Industry 4.0: The Unstructured Data Perspective
How to build a contextual platform that will be the launching pad for every one of your Industry 4.0 initiatives.